内存对齐和CPU伪共享问题
一、内存对齐1
1.1 什么是对齐
在计算机中访问一个变量,需要访问它的内存地址,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是:在访问特定类型变量的时候通常在特定的内存地址访问,这就需要对这些数据在内存中存放的位置有限制,各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
1.2 为什么需要内存对齐
- 不同硬件平台具有差异性,编译时将分配的内存进行对齐增加代码的可移植性;
- CPU访问内存时并不是逐字节访问,而是以字长为单位访问,32位CPU字长时4字节,64位是8字节。
参考如下未内存对齐和对齐情况下访问数据b的对比
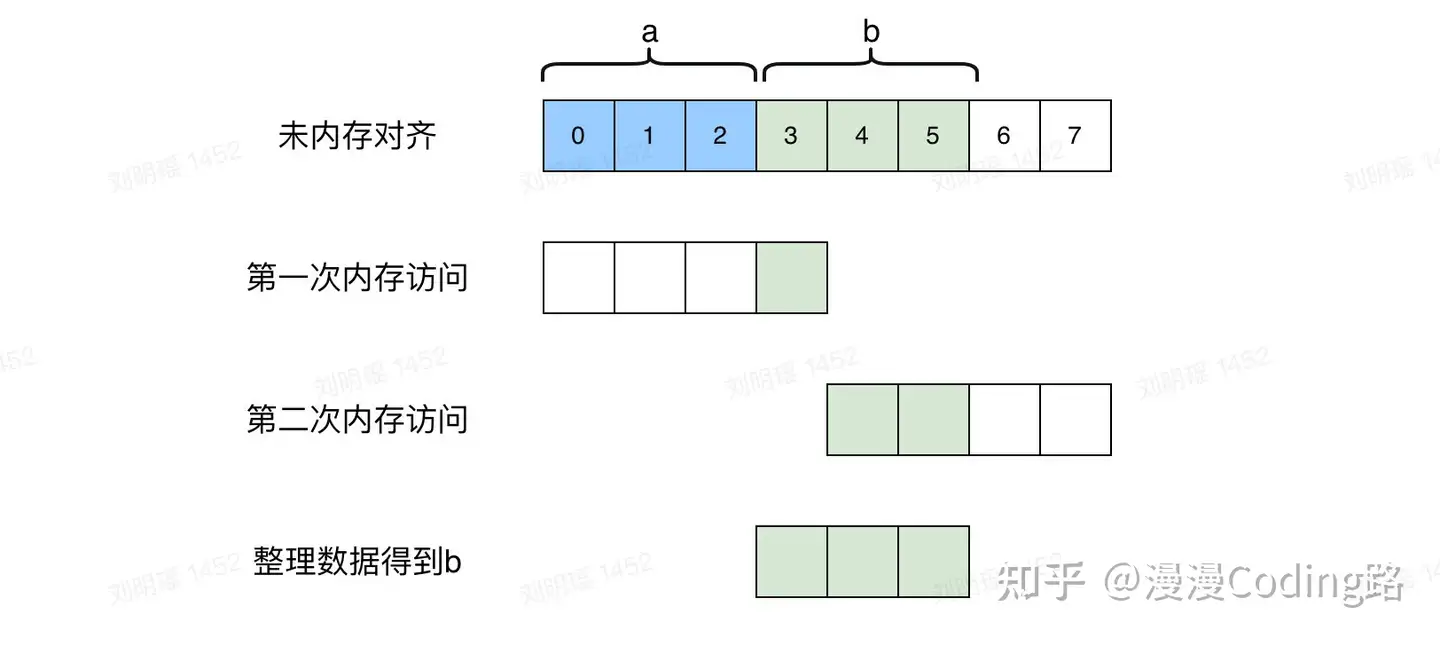
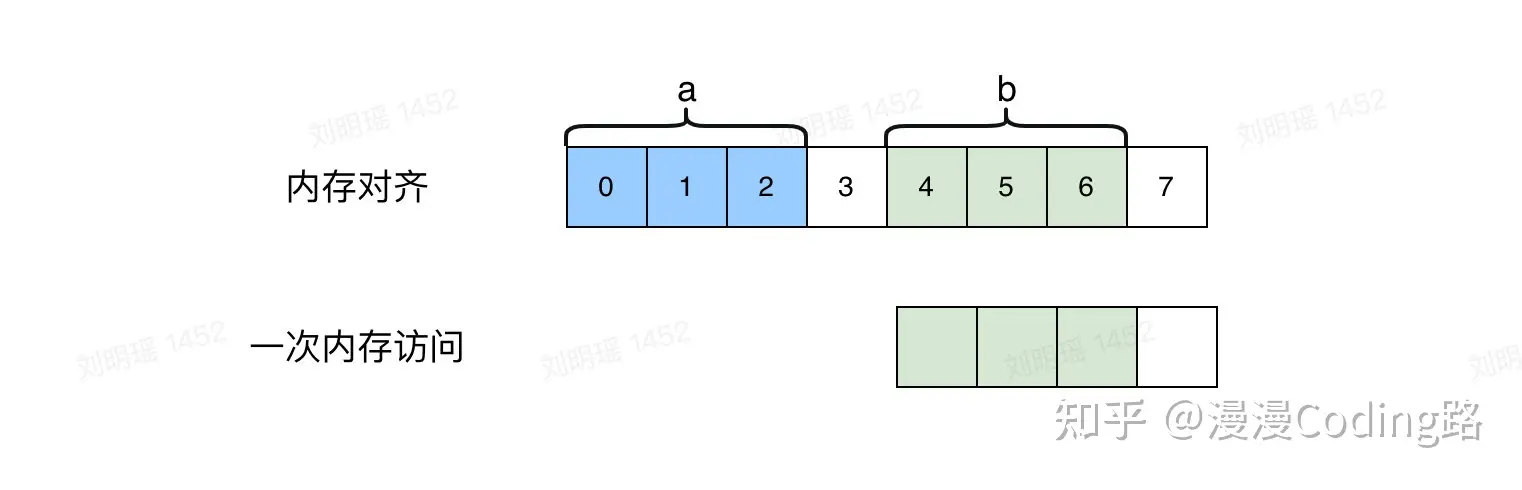
1.3 内存对齐规则
需要综合考虑CPU字长和具体类型占用长度。(以Go语言样例讲解)
Go语言的unsafe提供了对内存的操作2
unsafe.Sizeof函数返回操作数在内存中的字节大小,参数可以是任意类型的表达式,但是它并不会对表达式进行求值。unsafe.Alignof函数返回对应参数的类型需要对齐的倍数。unsafe.Offsetof函数的参数必须是一个字段 x.f,然后返回 f 字段相对于 x 起始地址的偏移量,包括可能的空洞。
内存对齐规则
| 类型 | 规则 |
|---|---|
| 成员对齐 | 基础类型变量需要被unsafe.AlignOf()整除 |
| 整体对齐 | 结构体需要保证结构体占用内存是unsafe.AlignOf()的整数倍,不足就填充空白 |
最终效果
| 占用内存 | 对齐后的效果 |
|---|---|
| 占用小于字长 | 一次访问就能得到数据 |
| 占用大于字长 | 第一次内存访问的首地址就是变量的首地址 |
1.4 数据对占用字节大小的影响
|
|
下图分别为结构体A和B的内存占用结构图


Java对应实体的内存占用计算方式参考附录资料3
二、缓存行和缓存行填充 4
2.1 CPU多级缓存
越靠近CPU内存越小但速度越快,三级缓存L3被单个插槽上的所有CPU核共享;主存由所有插槽的CPU核共享。
查找所需数据的顺序:L1 -> L2 -> L3 -> 主存,走得越远耗时越长。
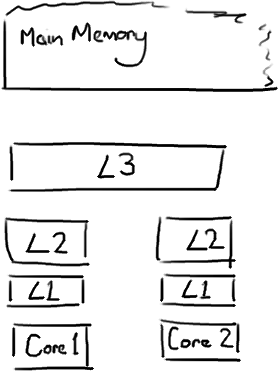
CPU缓存命中耗时参考5
| 从CPU到 | 大约需要的CPU周期 | 大约需要的时间 |
|---|---|---|
| 主存 | 约60-80纳秒 | |
| QPI 总线传输 | 约20纳秒 | |
| L3 Cache | 约40-45 cycles | 约15纳秒 |
| L2 Cache | 约10 cycles | 约3纳秒 |
| L1 Cache | 约3-4 cycles | 约1纳秒 |
| 寄存器 | 1 cycle |
2.2 缓存行
缓存是由缓存行组成的,通常是64字节(比较旧的处理器缓存行是32字节)。一个Java的long类型是8字节,因此在一个缓存行中可以存8个long类型的变量。
- 数组类型:连续加载,可以快速遍历;非彼此相邻的数据结构(例如链表):每一项都可能会出现缓存未命中。
- 一个类中的多个单独变量,在内存中紧挨着,加载其中一个变量时其他变量也会加载
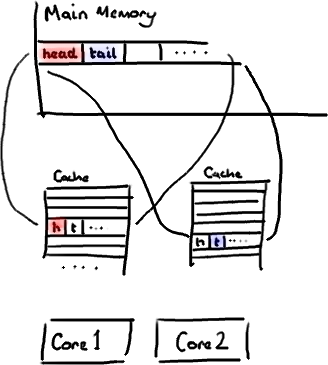
2.3 伪共享问题6
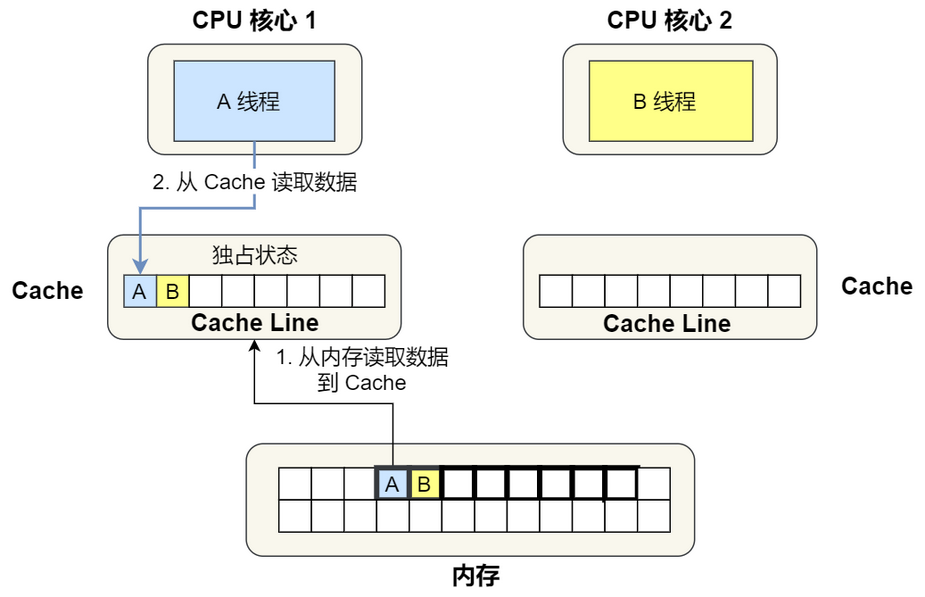
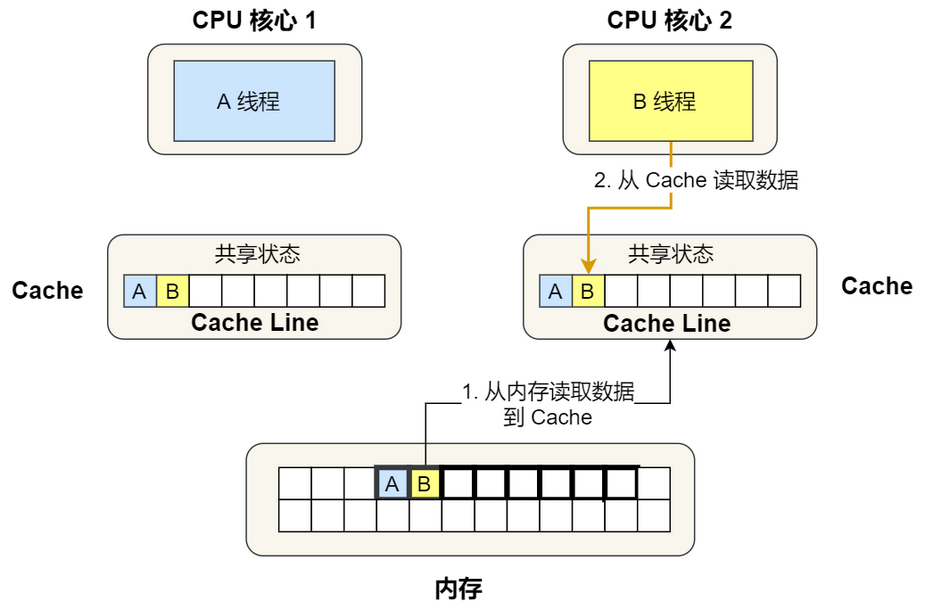
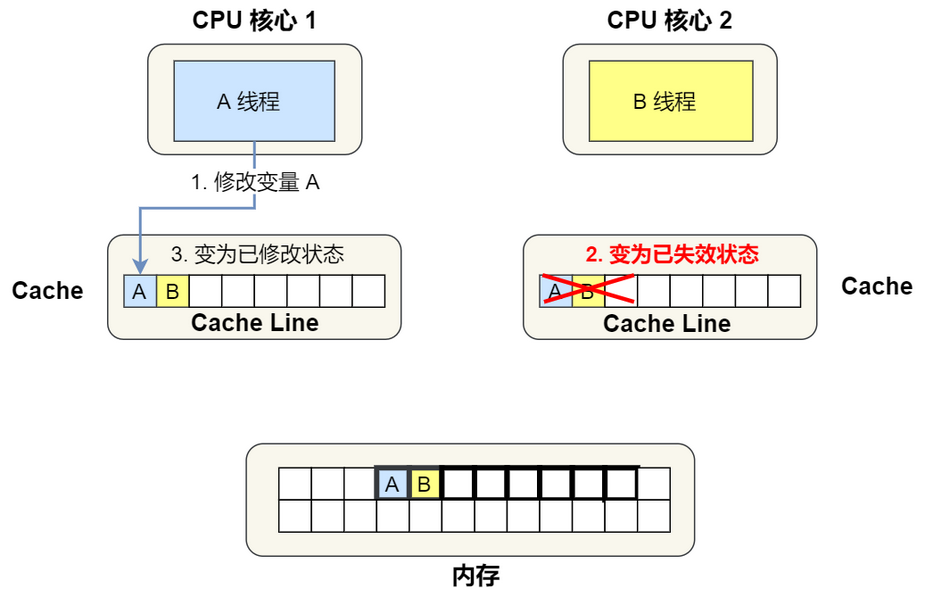
CPU1和CPU2缓存都有AB数据,只要一方修改了A或者B,就会导致对方缓存数据失效,虽然保证了缓存一致性,却失去的一定的性能。这就是所谓的伪共享问题。
- CPU核心1从主存中加载一个缓存行,并标记该缓存行的独占状态
E。 - CPU核心2也加载了同样地址的内存数据,在总线(BUS)上发了消息问问有没有CPU加载过该数据,发现CPU核心1有加载,于是CPU们都把这个数据设置为共享状态
S。 - CPU1改了变量A B的数据,发出了通知,CPU2知道之后,就将自己cache line中的数据设置为无效I。CPU1就将这个数据的状态标志设置为修改
M。 - 然后CPU2也要改数据了,他发现自己cache line中的数据无效了,所以需要CPU1把修改的数据写回内存,CPU2去内存中捞出来改,然后CPU将改完的数据设置为M。CPU1将当前cache line中的数据设置为I(无效)。
2.4 解决方案-缓存行填充
通过增加补全来确保ring buffer的序列号不会和其他东西同时存在于一个缓存行中。因此没有伪共享,就没有和其它任何变量的意外冲突,没有不必要的缓存未命中。
|
|
三、代码示例
指定并发线程数量,并发修改全局静态数据的数据,对比不同填充类型下运行同一代码逻辑的耗时
本示例代码样例:ns-cn/MemPadding
3.1 Java版本代码
Java版本样例:ns-cn/MemPadding/tree/main/Java,依赖shell环境和JDK
提供了编译运行的脚本
|
|
| 参数 | 说明 |
|---|---|
| type | 内存填充类型,可选(不填充选0、手动填充选1、自动填充选2) |
| thread-num | 线程数量,可选,默认为10 |
3.1.1 不填充
并发修改的数据类型为NoPaddingData,除实际数据外,仅包含数据value
|
|
以不填充的方式运行代码示例,并发线程数量为4
|
|
3.1.2 手动填充
并发修改的数据类型为ManualPaddingData,除实际数据外,包含额外的手动数据填充
|
|
以手动填充的的方式运行代码示例,并发线程数量为4
|
|
3.1.3 自动填充
并发修改的数据类型为AutoPaddingData,除实际数据外,
通过注解@Contended配合虚拟机参数-XX:-RestrictContended启用在运行时自动填充
|
|
以手动填充的的方式运行代码示例,并发线程数量为4
|
|
四、运行结果对比
本结果运行环境:
硬件:MacBook Pro 15-inch, 2018(2.6 GHz 六核Intel Core i7、16GB 2400 MHz DDR4)
操作系统:Ventura 13.1
JDK:1.8.0_352
OpenJDK 64-Bit Server VM (Zulu 8.66.0.15-CA-macosx) (build 25.352-b08, mixed mode)
| 方案 | 线程数 | 线程耗时 | 运行结果 |
|---|---|---|---|
| 不填充 | 4 | 45607 | 170.26s user 4.40s system 382% cpu 45.700 total |
| 手动填充 | 4 | 5085 | 19.21s user 0.45s system 380% cpu 5.173 total |
| 自动填充 | 4 | 5009 | 19.14s user 0.43s system 383% cpu 5.102 total |